Giới Thiệu Pandas Là Gì ? Cách Cài Đặt Pandas Python Xử Lý Dữ Liệu Với Pandas Trong Python
Thư viện vốn là một công cụ đắc lực hỗ trợ lập trình viên trong quá trình tìm hiểu, học lập trình và thực chiến trong các dự án thực tế. Với Python, có thể nói Pandas – một trong những thư viện thiết yếu. Với những ai còn chưa biết Pandas là gì, cách hoạt động và sử dụng nó ra sao thì bài viết dưới đây sẽ giúp các bạn hiểu rõ.
Đang xem: Pandas là gì
Pandas trong Python là gì?
Pandas là một thư viện Python toàn diện; một nguồn lực để thực hiện phân tích và thao tác dữ liệu; bất kỳ loại xử lý, phân tích, lọc và tổng hợp dữ liệu nào. Thư viện này được xây dựng dựa trên ngôn ngữ lập trình Python và có thể được sử dụng cho bất kỳ quy trình thu thập thông tin chi tiết từ dữ liệu nào.
Trong nghiên cứu khoa học dữ liệu, Pandas là một trong những công cụ quan trọng trong việc hỗ trợ, xử lý và phân tích dữ liệu với mã nguồn mở nhanh, mạnh, linh hoạt và dễ sử dụng,
Sử dụng Pandas để làm gì?
Về cơ bản Pandas có thể được coi là ngôi nhà dữ liệu của bạn. Thông qua thư viện này, bạn có thể làm quen với các dữ liệu của mình bằng cách sắp xếp, phân tích và biến đổi chúng.
Ví dụ: Bạn muốn khám phá tập dữ liệu được lưu trữ trong CSV trên máy tính của mình. Pandas sẽ trích xuất dữ liệu từ CSV đó vào DataFrame, một bảng tập hợp dữ liệu cho phép bạn làm những việc như:
– Tính toán số liệu thống kê, trả lời các câu hỏi về dữ liệu như giá trị trung bình, tối đa, tối thiểu của mỗi cột. Cột A có tương quan với cột B không? Sự phân bố dữ liệu trong cột C trông như thế nào?…
– Làm sạch dữ liệu bằng cách thực hiện những việc như xóa các giá trị bị thiếu và lọc các hàng và cột theo một số tiêu chí.
– Trực quan hóa dữ liệu với sự trợ giúp từ Matplotlib, biểu đồ thanh, đường kẻ, biểu đồ,….
– Lưu trữ các dữ liệu đã được làm sạch, chuyển đổi chúng thành CSV, tệp hoặc các cơ sở dữ liệu.
Trước khi bắt đầu mô hình hóa các hình ảnh trực quan phức tạp, bạn cần hiểu rõ về bản chất của tập dữ liệu và Pandas là con đường tốt nhất để thực hiện điều đó.
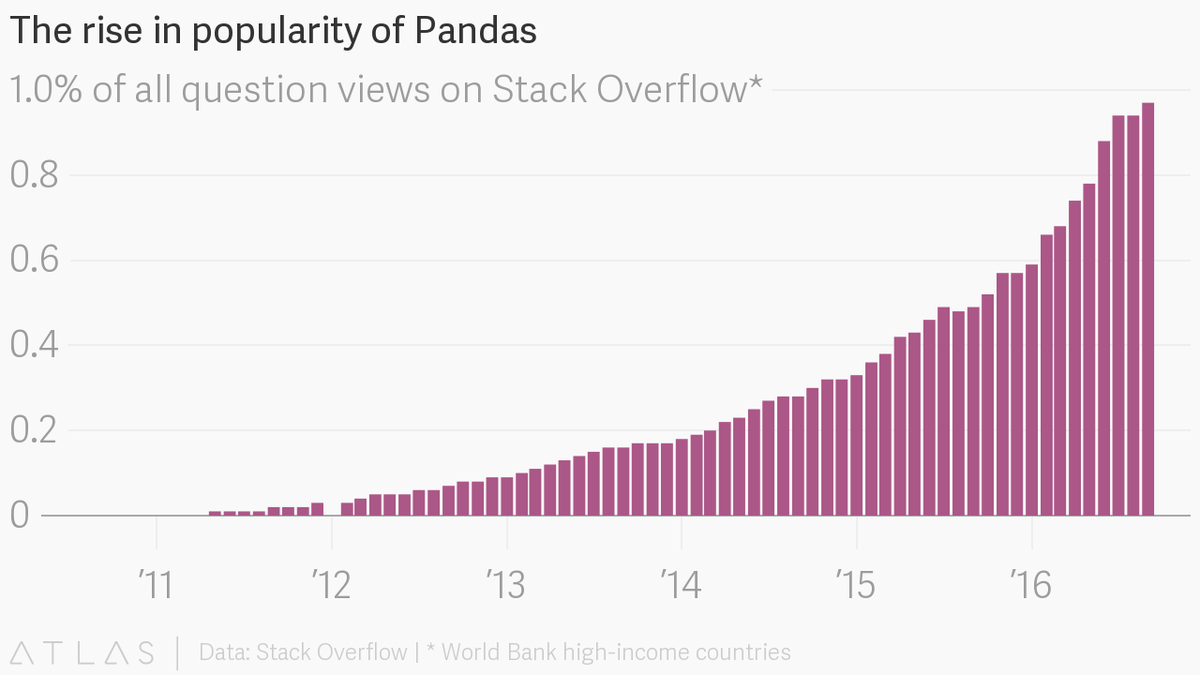
Sự gia tăng trong độ phổ biến của Pandas Python
Cách cài đặt Pandas
Pandas là một thư viện Python dễ cài đặt. Mở terminal program (với người sử dụng Mac) hoặc mở các dòng lệnh (với người dùng PC) và cài đặt nó bằng một trong các lệnh sau:
conda install pandas
Hoặc
pip install pandas
Các thành phần cốt lõi của Pandas Series và DataFrames
Hai thành phần chính của Pandas là Seriesvà DataFrame.
Một Series về cơ bản là một cột và một DataFramelà một bảng đa chiều được tạo thành từ một tập hợp các Chuỗi (Series).
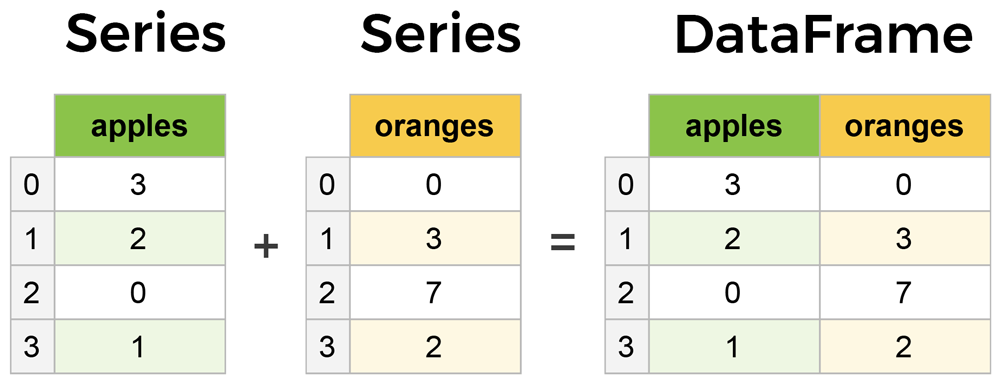
Các thành phần chính của Pandas
Cách tạo DataFrames trong Pandas Python từ đầu
Tạo DataFrames ngay bằng Python là điều cần biết và khá hữu ích khi thử nghiệm các phương pháp và chức năng mới trong docs của Pandas.
Xem thêm: Cách Mở Tài Khoản Chứng Khoán Ở Mỹ, Cách Mở Tài Khoản Giao Dịch Chứng Khoán Mỹ
Có rất nhiều các để tạo mới một DataFrame, một trong những lựa chọn tuyệt vời là sử dụng dict.
Ví dụ: Chúng ta có một quầy bán táo và cam, giờ ta cần có một cột cho mỗi loại trái cây và một hàng cho mỗi lần mua hàng của khách hàng. Theo mục đích đó, ta sẽ có lệnh như sau:
data = {
“apples”: <3, 2, 0, 1>,
“oranges”: <0, 3, 7, 2>
}
Sau đó chuyển lệnh này đến phương thức khởi tạo DataFrame như sau:
purchases = pd.DataFrame(data)
purchases
Kết quả
|
apples |
oranges |
|
|
0 |
3 |
0 |
|
1 |
2 |
3 |
|
2 |
0 |
7 |
|
3 |
1 |
2 |
Mỗi cặp khóa: giá trị (key:value) trong data tương ứng với một cột trong kết quả được xuất ra từ DataFrame. Các chỉ số của Data Frame này được cung cấp cho chúng ta thông qua các số từ 0-3, tuy vậy, chúng ta cũng có thể tạo riêng các chỉ số khi khởi tạo Data Frame.
Ví dụ, chúng ta có thể lấy tên khách hàng làm chỉ mục như sau:
purchases = pd.DataFrame(data, index=<"June", "Robert", "Lily", "David">)
purchases
Kết quả:
|
Apple |
Oranges |
|
|
June |
3 |
0 |
|
Robert |
2 |
3 |
|
Lily |
0 |
7 |
|
David |
1 |
2 |
Giờ đây, chúng ta có thể xác định đơn hàng của khách thông qua việc sử dụng tên của họ:
purchases.loc<"June">
Kết quả:
apples 3
oranges 0
Name: June, dtype: int64
Đọc dữ liệu từ CSVs trong Pandas
Với các file CSV bạn sẽ cần một dòng dòng đơn để tải dữ liệu:
df = pd.read_csv(“purchases.csv”)
df
Kết quả:
|
Unnamed:0 |
Apples |
Oranges |
|
|
0 |
June |
3 |
0 |
|
1 |
Robert |
2 |
3 |
|
2 |
Lily |
0 |
7 |
|
3 |
David |
1 |
2 |
CSVs không có các chỉ số như Dataframes nên tất cả những gì bạn cần là chỉ định index_cox khi đọc:
df = pd . read_csv ( ” Purchase.csv ” , index_col = 0 )
df
Kết quả:
|
Apples |
Oranges |
|
|
June |
3 |
0 |
|
Robert |
2 |
3 |
|
Lily |
0 |
7 |
|
David |
1 |
2 |
Ở đây chỉ mục được đặt là cột không. Bạn sẽ thấy rằng hầu hết các CSV không bao giờ có cột chỉ mục và do đó, bạn sẽ không cần lo lắng quá nhiều về bước này.
Đọc dữ liệu từ JSON trong Pandas
Nếu bạn có tệp JSON – tệp chứa dict của Python, Pandas có thể dễ dàng đọc tệp này thông qua lệnh:
df = pd.read_json(“purchases.json”)
df
|
Apples |
Oranges |
|
|
David |
1 |
2 |
|
June |
3 |
0 |
|
Lily |
0 |
7 |
|
Robert |
2 |
3 |
Pandas sẽ cố gắng tìm ra cách tạo DataFrame bằng cách phân tích cấu trúc JSON của bạn, đôi khi nó sẽ không làm đúng. Do vậy bạn sẽ phải đật orient đối số từ khóa phụ thuộc vào cấu trúc.
Đọc dữ liệu từ cơ sở dữ liệu SQL
Nếu bạn đang làm việc với dữ liệu từ cơ sở dữ liệu SQL, điều đầu tiên bạn cần làm là thiết lập kết nối bằng thư viện Python thích hợp, sau đó chuyển truy vấn qua pandas. Dưới đây, chúng tôi sẽ sử dụng SQLite để chứng minh.
Trước tiên, bạn cần cài đặt PySqlite3, vì vậy hãy chạy lệnh này trong thiết bị đầu cuối.
pip install pysqlite3
Hoặc chạy dòng lệnh này trong notebook:
!pip install pysqlite3
sqlite3 được sử dụng để tạo kết nối tới cơ sở dữ liệu mà sau đó chúng ta có thể sử dụng để tạo ra một Data Frame qua lệnh truy vấn Select. Do vậy điều trước tiên chúng ra làm là tạo kết nối với tệp cơ sở dữ liệu SQL
import sqlite3
con = sqlite3.connect(“database.db”)
Nhận thông tin về dữ liệu của bạn trong Pandas
.infor() là một trong những lệnh đầu tiên bạn phải chạy sau khi tải dữ liệu của mình, ví dụ:
movies_df.info()

Kết quả sau khi nhập lệnh .infor()
Lệnh.info() cung cấp các chi tiết cần thiết về tệp dữ liệu của bạn, chẳng hạn như số hàng, cột, số lượng giá trị rỗng, loại dữ liệu trong mỗi cột và dung lượng bộ nhớ mà DataFrame mà bạn đang sử dụng.
Việc xem nhanh kiểu dữ liệu thực sự khá hữu ích, hãy tưởng tượng bạn vừa nhập một số JSON và các số nguyên được ghi lại dưới dạng chuỗi (strings). Bạn thực hiện một số số học và một lỗi “không hỗ trợ toán hạng” xuất hiện vì bạn không thể làm toán với chuỗi. Gọi lệnh .Infor() sẽ nhanh chóng chỉ ra các cột mà bạn cho là số nguyên thực ra là các đối tượng chuỗi.
Cắt, chọn, giải nén Data Frame
Bằng cách sử dụng giá trị Null trong cột fillna(), bạn có thể trích xuất cột đơn giản bằng cách sử dụng dấu ngoặc đơn. Dưới đây là các phương pháp cắt, chọn và trích xuất mà bạn sẽ cần sử dụng trong Pandas Python.
Xem thêm: Các Loại Keo Non Toxic Glue Là Gì ? Mua Keo Sữa Ở Đâu? Cách Điều Chế Keo Sữa
Một điều quan trọng mà bạn cần ghi nhớ là, mặc dù có nhiều phương thức giống nhau, DataFrames và Series có các thuộc tính khác nhau, vì vậy bạn cần biết chắc loại mình đang sử dụng, nếu không bạn sẽ không nhận diện được các lỗi thuộc tính.
Kết luận: Khám phá, biến đổi, sắp xếp và trực quan hóa dữ liệu trong Pandas Python là kỹ năng thiết yếu trong khoa học dữ liệu. 80% công việc của bạn tư cách là là nhà khoa học dữ liệu là làm rõ các dữ liệu, do vậy, tận dụng Pandas là một trong những điều cần thiết bạn phải làm.